Wikipedia is a valuable resource to build Natural Language Processing systems for tasks such as Question Answering and Fact Verification. However, the sheer size of the resource can become an obstacle for new starters or those who think they haven't got the resources to crunch through the entire database. In my work on building resource for automated fact checking, I've relied a few strategies where Wikipedia can be processed on a single (8 core) desktop PC in about 4 hours – quick enough to try a few prototypes in a working day.
The tl;dr is to use a pipeline of workers to minimize the time the PC is spent idle, waiting for disk. Using the multi-stream files, the reader can be parallelized and using network based message queues, we can grow this beyond just a single PC.
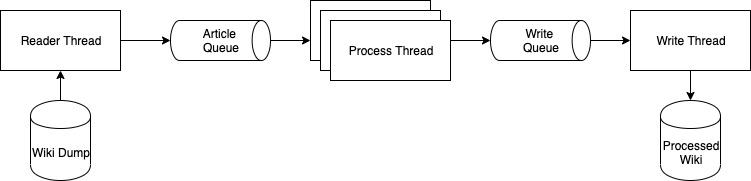
Reading the Wikipedia data
Wikipedia data is available in a variety of formats. For this tutorial, we'll be using the .xml.bz2 dump which can be downloaded from the Wikipedia archives over at https://dumps.wikimedia.org/. These are available as a multi-part download. however, we'll just use the large dump (around 18Gb) with the multi-stream parts combined. The format of the file is looks like enwiki-[date]-pages-articles-multistream.xml.bz2.
The Wikipedia file stream can be opened using the BZ2File() class in Python and passed to a custom sax.ContentHandler that can be used to extract the information we want from the file. This was inspired by a Stackoverflow post, however, I can't find the original to give credit to.
The file stream contains an XML dump with nested pages that contain ns, title and text elements as shown in following example.
<page>
<ns>0</ns>
<title>Page title</title>
<text>Wikipedia source for page text</text>
</page>The ContentHandler class has callbacks for startElement endElement and characters which are called when we encounter a new element inside the Wikipedia XML file. Each time we encounter a title and text tag, we should store this and when we encounter the closing page tag, we can call a callback which puts these onto the message queue.
import xml.sax
import logging
logger = logging.getLogger(__name__)
class WikiReader(xml.sax.ContentHandler):
def __init__(self, ns_filter, callback):
super().__init__()
self.filter = ns_filter
self.read_stack = []
self.read_text = None
self.read_title = None
self.read_namespace = None
self.status_count = 0
self.callback = callback
def startElement(self, tag_name, attributes):
if tag_name == "ns":
self.read_namespace = None
elif tag_name == "page":
self.read_text = None
self.read_title = None
elif tag_name == "title":
self.read_title = ""
elif tag_name == "text":
self.text_text = ""
else:
return
self.read_stack.append(tag_name)
def endElement(self, tag_name):
if tag_name == self.read_stack[-1]:
del self.read_stack[-1]
if self.filter(self.read_namespace):
if name == "page" and self.read_text is not None:
self.status_count += 1
self.callback((self.read_title, self.read_text))
def characters(self, content):
if len(self.read_stack) == 0:
return
if self.stack[-1] == "text":
self.text += content
if self.stack[-1] == "title":
self.title += content
if self.stack[-1] == "ns":
self.ns = int(content)
The reader is a stack-based parser that reads one page at a time from the dump and calls the callback with the text of an article. You could customize these for your own project. The other aspect is a lambda function ns_filter that allows us to select which content we should use. The article namespace is ns:0. Other namespaces are listed here: https://en.wikipedia.org/wiki/Wikipedia:Namespace
The default namespace filter I use is lambda ns: ns==0
Article Processing
The article processing would do some cleaning of the Wikipedia markup and some processing such as sentence splitting or tokenization.
def process_article():
while not (shutdown and aq.empty()):
page_title,source = aq.get()
text = clean(source)
doc = nlp(text)
sents = []
for s in doc.sents:
if len(sents) > 0:
# Fix some spacy sentence splitting errors by joining sentences if they don't end in a period
if len(str(sents[-1]).strip()) and str(sents[-1]).strip()[-1] != ".":
sents[-1] += str(s)
continue
sents.append(str(s))
out_text = "\n".join(sents)
fq.put(json.dumps({"page": page_title, "sentences":out_text}))
Cleaning up Wikipedia source is a messy process. While tools such as mwparserfromhell help, they often miss bits which need to be cleaned. You can find some useful (but imperfect) functions in the FEVER library: https://github.com/awslabs/fever/blob/master/fever-annotations-platform/src/dataset/reader/cleaning.py
Saving to Disk
Saving to disk from the filequeue is simple
def write_out():
while not (shutdown and fq.empty()):
line = fq.get()
out_file.write(line+"\n")Putting it all together
Here we create a handful of worker processes that listen to the article queue aq. We create the Wiki reader and set the callback to aq.put. We also create a status process that will report the number of items read and the depth of the queues every second.
def display():
while True:
print("Queue sizes: aq={0} fq={1}. Read: {2}".format(
aq.qsize(),
fq.qsize(),
reader.status_count))
time.sleep(1)
if __name__ == "__main__":
shutdown = False
parser = ArgumentParser()
parser.add_argument("wiki", help="wiki dump file .xml.bz2")
parser.add_argument("out", help="final file .txt")
args = parser.parse_args()
manager = multiprocessing.Manager()
fq = manager.Queue(maxsize=2000)
aq = manager.Queue(maxsize=2000)
wiki = BZ2File(args.wiki)
out_file = open(os.path.join(args.out),"w+")
reader = WikiReader(lambda ns: ns == 0, aq.put)
status = Thread(target=display, args=())
status.start()
processes = []
for _ in range(15):
process = Process(target=process_article)
process.start()
write_thread = Thread(target=write_out)
write_thread.start()
xml.sax.parse(wiki, reader)
shutdown = True