This year's ACL 2022 best paper was on the topic of incremental parsing. Parsing is something that's been well studied in the NLP, Computational Linguistics fields before. So why does this year's best paper laud a work on a topic that some might have considered out of fashion since deep learning and transformers have taken over the majority of NLP tasks? This blog post will describe the approach taken by the authors and highlight some of my thoughts on the positives and negatives and what other authors submitting to *CL venues could adopt to improve their papers in the future.
Avoiding speculative parsing
The contribution of this paper is a mechanism that avoids speculation when ambiguity is encountered in a sentence. In the example in the paper and talk, the authors demonstrate how left-to-right parsing of a sentence introduces two valid branches which must both be considered. One path is valid, but the other would lead an incremental parser to a dead-end.
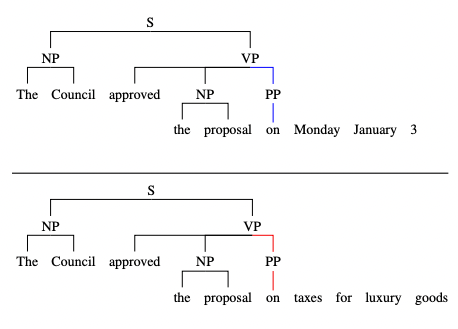
The goal of the paper is to obviate the need for speculation in incremental parsing. Speculation is computationally expensive and requires committing to a decision with incomplete evidence.
Conventional incremental parsing uses a tree equivalent schema. Each token in the sentence is assigned a label and that sequence of labels yields a set of instructions that can be directly compiled into a tree. The issue with this approach is that in some cases, the model must commit to one of these labels in the presence of incomplete evidence – which may yield an incorrect tree.
While in previous work the schema is hand-defined, the novelty of this paper is to learn a latent set of actions that is tree equivalent. The bulk of the computation in previous work is performed in the representation encoder that outputs the tag sequence for the sentence. In contrast, this work learns a tree-equivalent representation that is converted to a tree in an end-to-end manner.
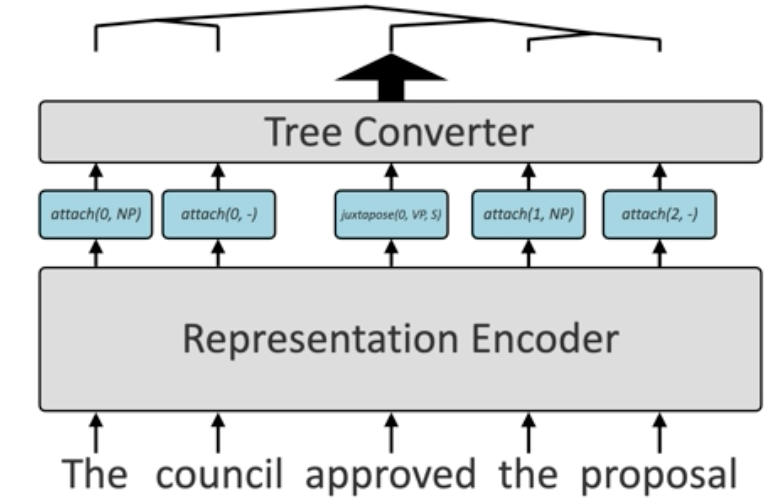
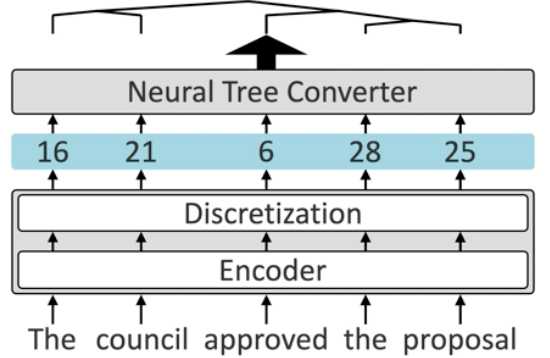
Each token is encoded as a vector that is then quantized at the discretization layer of the encoder module yielding a sequence of numeric tags which are then converted into a tree structure. The encoder is computationally heavy whereas the neural tree converter is lightweight. Despite ambiguity in the sentence, the tag sequence up to and including the ambiguous tag is the same. The different tree structure is only resolved after the final tag is observed. The tags act as representations of the tokens as they arrive, rather than concrete actions.
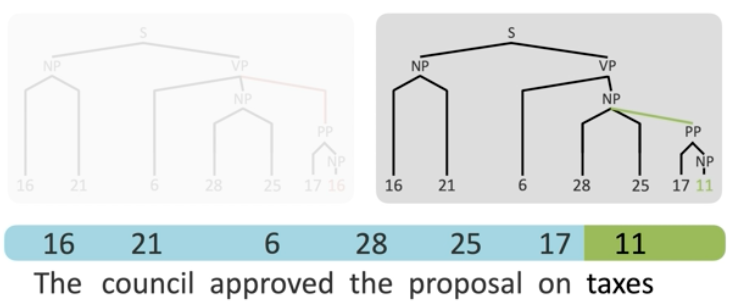
The model doesn't exceed state of the art accuracy
One fault I find of some papers and the reviewing process in ACL conferences is the need to chase state of the art. The model performs on-par with contemporary approaches, but the accuracy doesn't exceed previous work. Is this a problem? No. While Span classification (Kitaev et al., 2019) and Attach-Juxtapose (Yang and Deng, 2020) have marginally higher F1 scores in tree construction, both of these approaches exploit bidirectional encodings with a BERT model.
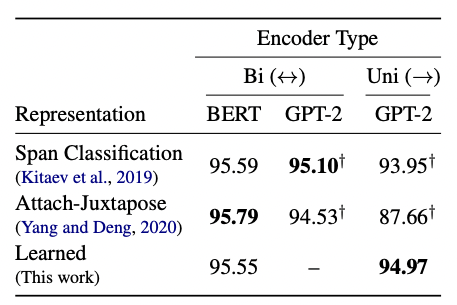
What's actually quite exciting is that this paper makes achieves a on-par F1 score despite only using a unidirectional encoder. This means that the parse tree can be constructed while the token sequence is being streamed in, allow applications for real time uses such as voice assistants. What is also interesting is that without the bidirectional encoders, the "state of the art" systems perform less well than the proposed method highlighting a dependency on fixed encoder schemes to "look ahead" rather than incrementally parse the sentence. Other experiments in the paper evaluate the number of tags to use (showing diminishing returns up to 256 tags).
Why is this paper worthy of a best paper award?
I've never received an award, nor been on a judging panel. But there are some positive parts of the paper I don't normally see in other works. If I was on the judging panel, this would have influenced my decision.
- "Undoing research" the task setting an established dataset with decades of research in building linearized incremental parsers. Many state of the art methods are a result of manual choices of label schemas as well as advancements in modelling with bidirectional representations. From Shift Reduce Parsing Arc-Eager to Juxtapose, researchers have devised hand-crafted tagsets and schemas to linearize the tree construction process. This paper indicates that better schemas can be learned.
- "Faster decoding": without beam search or need for backtracking, the real-time runtime of this algorithm can be much faster. Performing greedy search instead of 5-beam search gives a 5x speedup. The model appears to be trained to induce the optimal path through the tagset and doesn't require the beam search to find this. Similarly, because there is no speculation at the "heavy" encoder phase, there is no backtracking.
- Analysis: not all papers perform a rich analysis of why the method works and what can be learned from the technique. This paper has several studies that help the reader better understand why this method is interesting and show patterns and regularities that help justify the design choices in the paper.