This post is a summary of the "Next Big Ideas" session at ACL: established members of the NLP community formed a panel presenting their view of the future of the field.
The session featured a series of talks and a panel from Heng Ji, Mirella Lapata, Dan Roth, Thamar Solorio, Marco Baroni, Hang Li, and Eduard Hovy. The panel was moderated by Iryna Gurevych.
Talk Synopses
Heng Ji: Falling in Love (again) with Structures.
This big idea focused on a previously explored big idea from the early 2000s: cross-lingual information extraction and automated text summarization. Information Extraction and Text Summarization share the same goal: delivering the most important information to the users. However, have different underlying assumptions over structure.
NLP today is sequential and flat - implicit representations, sentence input. Large scale language models work well on multiple tasks and languages without specific annotation required for models. But at these sizes, models can only be trained by large-sized research groups and corporations with the appropriate computing resources.
While research previous research had a goal of extracting information from a the entire corpus, with the contemporary machine-learning methods only sentence-level information extraction was tested and evaluated. However, with the availability of new model types and the ability to capture long-range dependencies, the talk points to a potential future where both document-level and corpus-level information extraction could be performed again.

However, what most large-scale methods (such as BERT-based IE) don't take advantage of is the structures in the inputs or the outputs. However, this is a feature of many tasks (e.g. structured knowledge bases, chemical formulae, event schemas, parse trees etc) and is beneficial to some tasks in low-resource settings.
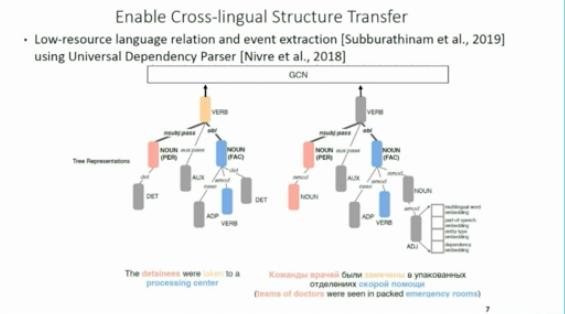
There are two issues: how to acquire knowledge and how encode it.
Structured data is widely available in natural structures (e.g. the web) or curated forms (such as knowledge graphs). Some of these structures can be learned from large-scale models from unstructured data to further support extraction.
The advantages of structured knowledge are that: it is compositional and can be used for cross-sentence reasoning, generalizable and can be used for synthesis and updating to unseen tasks, transferable serving as a bridge for unseen tasks or languages, explainable giving an intermediate representation that expresses some fact, and also has utility as users can provide feedback and influence the results.
There are many ways to encode this structured too: pre-trained language models provide a mechanism for type discovery and data augmentation, graph neural networks could be used to update embeddings based on network structure, constraints could enforce structure during inference, and self-supervision could be use to align to structures.
The concluding remarks of the talk were that "flat" models in NLP will come and go and that flatness is a property imposed by the models that we are using. However, in the natural world structure exists and will remain for the future.
Mirella Lapata: Paying Attention to Stories
The way children learn about society, how culture is kept alive, and how values are instilled is through stories. Stories are everywhere, e.g. movies, podcasts etc. Understanding the science of stories is well studied and has been the subject of hundreds of books.

Stories have shapes and structure (e.g. orientation, rising action, climax, falling action and resolution) and also themes that are recurrent (e.g. man-vs-beast) is in many stories (e.g. Jaws, Jurassic Park, Beowulf). Mirella's argument is that if we crack the issue of stories, we crack the issue of natural language understanding: it allows us to ask contextual questions over very long passages of texts.

To overcome these challenges, we must consider challenges of data, modelling, and evaluation.
Each book, movie, podcast, or script is a lot of data but also is a single datapoint. It is not feasible to annotate large collections of stories for the myriad of questions that humans would want to ask. As a community we must use automated and self-/semi- supervised methods to make use of the data with minimal human intervention.
Stories exceed the memory capacity of today's conventional modelling choices. For example, models such as transformers have fixed input sizes and do not scale well to large inputs beyond hundreds of tokens. Stories, in contrast, contain thousands of words and have dependencies over many sections. There are many dependent and plot lines, character interactions and causal actions in the stories that must be understood. We need to think about new architectures with models that interact: some models would be in general purpose, some would be specialist.
The talk then concludes by pointing to resources in the NLP community including workshops of storytelling, narrative understanding, and automatic summarisation for creative writing.
Dan Roth: It's time to reason
A lot of machine learning based approaches to question answering exploit patterns and regularities in the inputs for a learning signal. Asking questions such as "what day of the year is the longest in Boston?" would give the same answer as if the question is also about New York. But if you change the input to ask a question about Melbourne, for example, the expected answer should be different. Learning these connections from a corpus of text only facts only allows a model to memorize existing facts and cannot generalize to unseen cities or places where the latitude/longitude is needed to condition the generation of the answer.

At the heart of this process is a planning process which is needed to reason which information is needed, find the correct information, and to generate the answer from a set of ground truth information. There are a lot of reasoning questions that depend on combining multiple pieces of world knowledge that is explicitly written and tacit knowledge that is not always expressed. An agent must devise a plan and access external resources to reason about an answer. We need to extract, contextualize and scope the answers, reason about quantities, and provide a reason about why we gave an answer (reasoning is about the reason).
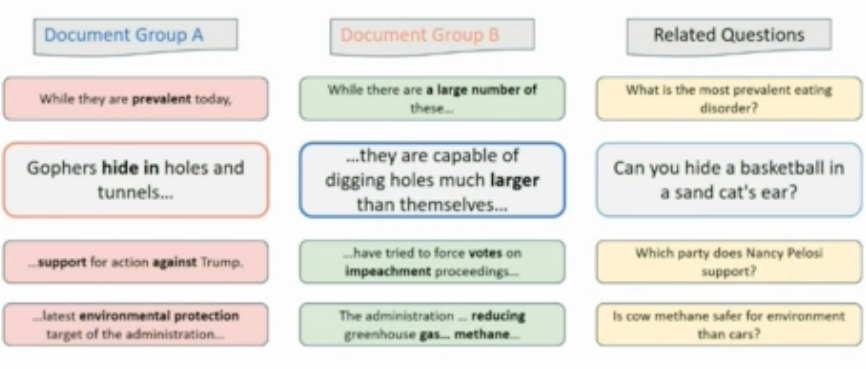
The second point of Dan Roth's talk was to also consider how we supervise model training. Data for most tasks is collected by simple minded annotators performing data collection and labelling for a single objective. However, in childhood, humans learn through correlating different expressions of the same signal or event. Dan introduced a potential form of supervision for models as "Incidental Supervision". There can be many forms of incidental supervision and one example he gave was learning from texts with the same meaning. One event may be expressed in multiple different sources with differentiation.
What we do today is not sufficient to deal with the sparse world both for reasoning or for supervising training.
Thamar Solorio: Human Level Multilinguality
Half of the world's population use two or more languages in every day life and speakers code-switch between languages in the same utterance. However, NLP technology caters to monolingual speakers. When NLP discusses "multilingual" models, we assume that the input is one language per utterance and the community could further strive for true multilingual NLP technology where more than one language per utterance is used.
Multilingual settings are increasingly relevant for applications of NLP in the community, for example: voice assistants, social media usages, and chatbots. In formal settings for healthcare, this is equally as important. There are several challenges though compounded by limited resources and noise in the data and issues around transliterating and informal mappings between different scripts. Even if we know what languages are going to be mixed, we don't know when and how the languages will be mixed. The diversity of switching depends on the context, the speakers, and the power dynamics of the languages.
There are many related disciplines that computational linguistics and NLP researchers should be collaborating with expert linguists sociolinguists and language acquisition experts. The takeaway is that users shouldn't have to leave their linguistic identities behind when using NLP systems.
Marco Baroni: Unnatural language processing
In natural language processing: we have moved through several methods in recent years from training on specific data, to fine-tuning pre-training models, to massive pre-trained language models without fine-tuning and only using prompt engineering.
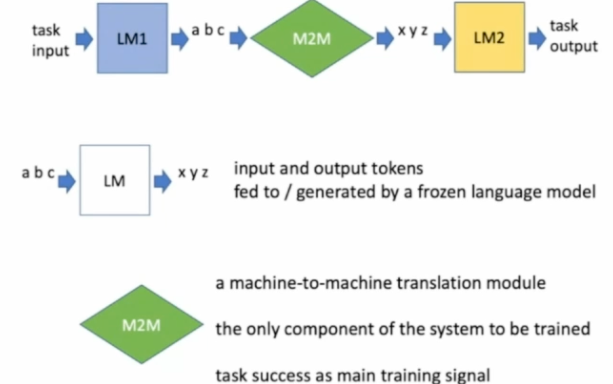
Marco's big idea was machine-to-machine bridging models could be used to allow coordination between multiple services that have inputs and outputs in a natural language. The idea seems similar to be a message bus or middleware layer to coordinate many 3rd party services (e.g. LM1 could be a voice assistant and LM2 could be a shopping service). The LMs would be frozen and the M2M models would be learned in-situ.
This is a new task, so this would require new methods for training and collecting data for supervision. There are challenges about understanding whether an interlingua emerges and whether these middle languages are interpretable and compositional. The findings could yield further insights about the properties that are not revealed with natural languages alone.
This idea seems quite futuristic but builds upon research in many related NLP and ML research domains including: Socratic Models, Adaptors, and Prompt Engineering, Deep Net Emergent Communication
Eduard Hovy: Rediscovering the need for representation and knowledge
Natural language processing can be viewed as a transduction task: converting one string or structure to another. If you do the task by hand, it would be useful to have some features that you look out for to help do your job easier. Neural networks help do that in automated way: learning which combinations of the input are useful features for the downstream task. Just like rule-based systems doesn't solve problems completely, neural networks with billions of parameters also haven't solved all of NLP problems completely despite being trained and exposed to a large portion of the web. There are many implicit or tacit facts that must be accounted for that aren't stated clearly in writing.

There are many implicit facts needed to answer these questions or perform the inferences with rare knowledge that doesn't appear in the training data. No knowledge in the language model means that the model cannot learn a transformation to generate the answer. In contrast, people have lived in the world and can perform these inferences intuitively because they've experienced a wide range of day-to-day activities.
There are gaps in reasoning in the models and we must be are of these and identify strategies to fill them. However, we cannot know well in advance what these gaps actually are.
To build systems that understand user's goals, research must be grounded in psychological frameworks. For example, from Maslow's hierarchy of needs or goal hierarchy. You must find a sensible set of set of types that provide a rationale or reason behind the sentence. But this is not something that a machine can easily do.
Similarly in common sense knowledge schemas, Eduard gave an example of the DARPA KAIROS program: building a set of schemas that describe the evolution of events. These schema structures are very difficult to learn from large language models and lot of the set of structures have to be manually added based on human intuition and experiences.
And finally, in groups of people people play different roles in communities. For example in Wikipedia, editors perform different tasks such as checking grammar, verifying facts, and removing vandalism. To identify these sorts of groupings, we need human intervention to build a schema defining these interactions.
For interesting NLP, where information is convoluted or difficult to access, we have to on that human intuition to decide what kind of knowledge we care about, what data contains it, how to make inferences, and how to evaluate it. If we can't find ways to automatically elicit this information, we will reach the same asymptotes that we have seen with rule-based systems, supervised learning, and now with large language models. We need to start thinking again about the structures and knowledge representations we need. NLP must stop being lazy – there's more to understanding language than corpus data alone.
Hang Li: Neural Symbolic Architecture for NLU
In psychology, researchers have proposed a dual system for how we think. Hang Li's proposal was to replicate the System 1 and System 2 duality in Natural Language Processing and combine local reasoning with programs with analogical reasoning with neural representations and combine the output for a final prediction.
In a task such as natural language inference, we perform entailment prediction using neural networks that have no formal well-grounded method for numerical reasoning. The neural based approaches doesn't work well for all types of these numerical problems and cannot always generate an accurate answer. Similar architectures are used for tasks such as question answering. Again, seq2seq neural models do not explicitly model numerical reasoning.

As an alternative to using the analogical reasoning that is common in NLI and QA models, we could exploit program-based methods for explicit reasoning over numerical values: translating texts into programs. The encoder and decoder act as a translation from input text into programs.
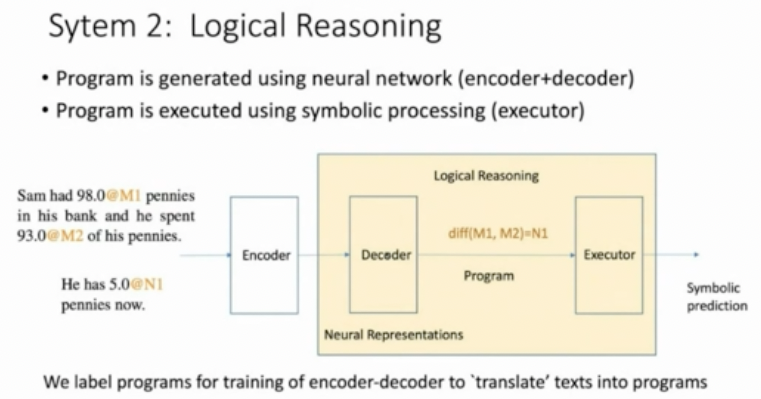
A mixture of experts can combine both systems. Experimental results show improvements for combinations of models than either approach alone. However there's a lot of challenges around data generation and labelling that need to be addressed.
Slides are content copyright of the respective authors and are not subject to the creative-commons license of this website content.